Let’s Talk About AI Libraries!

Pedro Oliveira
Lead Web Developer
14 min read • November 15, 2022
The possibility of having machines that mimic how humans think rationally and make decisions opens up a world of possibilities. Discover more about AI Libraries in this article.

load-blog-lets-talk-about-ai-libraries
Artificial Intelligence (AI) is one of the areas that has increasingly entered our lives in recent years. The possibility of having machines that in some ways mimic how humans think rationally and make decisions, from the simplest to the most complex, opens up a world of possibilities to transform and improve areas such as health, agriculture, space exploration, sports, the automotive industry, and others. Although we might not realize it yet, AI is already very present in our everyday lives. For example, social media platforms use so-called recommendation systems that, in short, prioritize the content they believe the user will prefer. The decision to present a certain type of content to a given user takes into account their personal data (age, gender, etc.) and the interactions they have with the different types of content on the platform. In addition to social media, personal assistants (e.g., Google Assistant, Siri, Alexa), smartphones, cars, and many others already have some form of AI embedded into them. The presence of AI in our lives will continue to grow as we better understand how it works and how it can be applied in different scenarios.
Whether it’s a chatbot, optical character recognition (OCR), text analysis, facial recognition, or any other type of AI task, we are seeing an increasing demand for these AI functionalities in the solutions our customers are having us build, as they become more aware of AI in general and the benefits it can bring. With this in mind, we decided to spend some of the time we have for self-learning during the week developing a framework that could tackle some of these AI tasks so that we can easily deploy it across multiple projects.
In this article, we are going to share with you our progress, how we approached the development of this framework, what technologies we used, what tasks we wanted the framework to accomplish, what concepts we learned, and what difficulties we encountered along the way.
Before we started developing the framework, we had to decide what tasks we wanted the framework to perform in this first phase, what technologies we wanted to use for development and create an architecture for the framework.
In terms of tasks, we decided that the framework should be able to extract entities and intentions from any text and perform predictive maintenance. The decision to extract entities and intentions was made due to the fact that this is one of the tasks within Robotic Process Automation (RPA). Essentially, RPA consists of software that can be easily programmed to perform routine activities, currently carried out by human workers, in a controlled, flexible, and scalable manner. This relieves employees from doing repetitive and error-prone tasks and allows them to focus on more meaningful tasks, which ultimately, helps organizations to be more productive and efficient. The decision to include predictive maintenance in the initial phase of the framework stemmed from the fact that nowadays, modern equipment is fitted with numerous sensors, and we felt it was important for our framework to be able to receive data from these sensors and forecast when a piece of equipment would need maintenance to avoid future failures.
To better understand these two tasks and get a better idea of how to solve them, we had to dive deeper and explore some of the approaches the community uses to solve them. Entity and feature extraction is a subfield of natural language processing (NLP), a branch of artificial intelligence whose main goal is to give computers the ability to understand the text and spoken words in a similar way to humans. To solve NLP-related tasks, we have found the following concepts and approaches:
- Bags of words – is an approach that transforms text into matrices. It does not understand the word order in a sentence, but it can detect the presence or absence of words. To use this approach, you need to define the words that you want the model to understand. This approach is quite limited since it cannot understand the context associated with the words, but it can be useful for problems such as text classification (for example, to detect whether the text of a particular email is spam or not).
- N-grams – is a sequence of N words. An N-gram-based model predicts the occurrence of a word based on the occurrence of the preceding N – 1 words. Examples of tasks where this type of model can be used are auto-completion and spell-checking.
- Word Embeddings – a set of techniques in which individual words are represented by real number vectors in a given vector space. Words that have similar meanings have similar numbers in the vector. An example of word embedding is below.
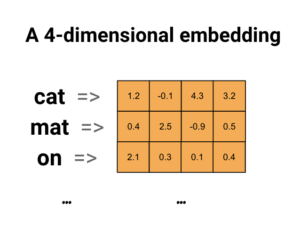
- Embedding layers – a type of layers that can be incorporated into neural networks to solve specific neural language processing tasks. Their values are adjusted using backpropagation algorithms.
- Word2Vec – this is a family of model architectures and optimizations that can be used to learn word embeddings from large datasets. Word2vec models take words from a large text corpus as input and learn to output their vector representation (word embeddings).
- GloVe – is an unsupervised learning algorithm for obtaining vector representations (word embeddings) for words. In this approach, a large matrix of co-occurrence data is created, counting each word and the frequency with which it appears in a context within a text corpus. The text corpus is usually evaluated in the following way: for each term, context terms are searched in a range before and after the term. In addition, the words that are further away from the original keyword are given a smaller weight compared to the closer words.
- Transformer – it is a neural network architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies in a simple way. Models based on this architecture do not compute the representations of their inputs and outputs using recurrence or convolutional techniques, but rely on “attention mechanisms.” Some examples of transformer-based models are GPT-3, LaMDA, BERT, T5, and others.
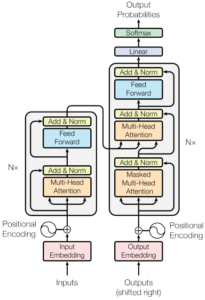 (Transformer architecture)
(Transformer architecture)
Predictive maintenance combines data science and predictive analytics to estimate when a device might fail so that corrective maintenance can be planned before the point of failure. The goal is to schedule maintenance at the most convenient and cost-effective moment, in order to maximize the life of the equipment. Predictive maintenance can be done in two ways: Classification and Regression. In the first method, we try to predict whether a failure is imminent in the next n steps, and in the second, we try to predict how much time is left until the next failure. To solve predictive maintenance problems, we can use the more classic machine learning algorithms such as Support Vector Machine (SVM) or K-Nearest Neighbors (k-NN or KNN), or we can follow the Deep Learning route and use auto-encoders, recurrent neural networks (RNN), and long short-term memory (LSTM) networks. To give you a little more context, we will give you a brief summary of how the previously mentioned algorithms work.
- Support Vector Machine – is one of the most popular machine learning algorithms, which is used for classification as well as regression problems. Its goal is to create the best line or decision boundary that can segregate n-dimensional space into classes so that it can easily put a new data point in the correct category in the future. As we can observe in this article, it can be successfully applied to predictive maintenance.
- K-Nearest Neighbors – it is a supervised learning classifier, which uses proximity to make classifications or predictions about the grouping of an individual data point. It can be used for either regression or classification problems, although it is typically used as a classification algorithm, working off the assumption that similar points can be found near one another. They can be used for recommendation engines, pattern recognition, and predictive maintenance.
- Auto-encoder – is a type of unsupervised neural network that learns to effectively compress and encode data, and then learns to reconstruct data from a reduced encoded representation into a form that is as close as possible to the original. It is considered an unsupervised neural network because the data used to train the network is not labeled/annotated, meaning that the model itself must learn how to interpret and process the data. Here is an example of its application in predictive maintenance.
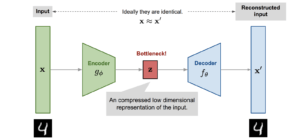
(High-level overview of an Auto-encoder model)
- Recurrent neural networks – it is a type of neural network where the connections between units form a directed graph along a sequence. This factor enables these types of networks to exhibit dynamic temporal behavior for a time sequence. They are suited for challenging tasks such as speech recognition or handwriting recognition.
- Long-Short-Term Memory Networks – these types of networks are an expansion of RNNs that use LSTM units to learn long-term dependencies. They are built to remember information over long periods of time. This makes them useful in solving tasks such as speech recognition, market forecasting, and others. Predictive maintenance is also a good example of their use, as you can read here.
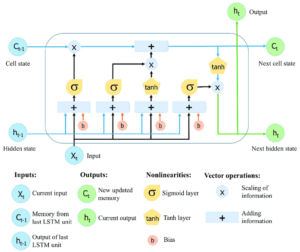
(Structure of an LSTM network)
As for the implementation of the tool, we have determined that we would approach it by abstracting away the use of the most common open-source machine learning libraries. With this approach, we can quickly add as many new problems to solve as we want, and we can choose any library without having to commit to a specific one. We have achieved this by creating a common interface that can be used by any library, so it always behaves the same regardless of the problem being solved.
With this in mind, the following diagram shows the chosen architecture:

The ProblemSolver is the main class and entry point through which the developer would interact with the tool. You pass the problem you are trying to solve, the data to be used, and the format of said data. Internally, the data is converted into a Pandas data frame that is used by the concrete implementation of the ProblemInterface and that defines how a problem looks like. For a problem, you can train a custom model that will be assigned with an ID and saved to the disk as a pickle, or you can make a prediction using an existing model on the disk.
The current problems being solved are:
- Entity extraction – Where you pass text and you get which entities are present on the text, where and what type they are;
- Binary classification – Where you pass tabular data and try to predict if the table row will have a label or not;
- Regression – Where you pass tabular data and try to predict the concrete value of a table column for a row.
In terms of technologies, we decided to use Python for the development of our framework, as it is one of the most widely used programming languages in general and is often used for machine and deep learning tasks. Besides Python, for the entity extraction problem we used Spacy, an open source, widely used, NLP-oriented library that has a particular feature that interested us and that is not very common in other NLP-oriented libraries, namely the support of the Portuguese language from the beginning. For the binary and regression problems, we used Pycaret, another open-source and widely used library that contains many modules for solving tasks in the realm of classification, regression, NLP, anomaly detection, and many others.
As mentioned before, we wanted to have the freedom to choose which libraries to use in the concrete implementations, as some are better suited to one type of task than others, and also wanted an easy and straightforward way for developers to interact with the framework. Since the concrete implementations of the framework are always behind the proposed abstraction layer, developers will not need to worry about future updates to those implementations and can easily integrate new implementations, as they will always follow the abstraction layer. It is important to highlight that the framework in question is ready to provide helpful solutions to our customers, however, its development is far from over. We intend to continuously improve the framework, in order to provide quick answers to the most prevalent machine learning tasks, so that they may be swiftly incorporated into the products our customers are having us build. For future steps, we intend to add new tasks to be solved, such as OCR, image classification, object detection, and object tracking, and want to improve the results obtained in the tasks mentioned in this article. Stay tuned for upcoming articles regarding the updates of this framework. 🙂
Pedro Oliveira
Lead Web Developer