



Artigo
Vamos Falar Sobre Bibliotecas de IA!
A possibilidade de ter máquinas que, de certa forma, imitam o ser humano na forma de pensar e de tomar decisões, das mais simples às mais complexas, abre um mundo de possibilidades. Saiba mais sobre Bibliotecas de IA neste artigo.
November 15, 2022

A Inteligência Artificial (IA) é uma área que, nos últimos anos, tem estado cada vez mais presente no nosso quotidiano. A possibilidade de ter máquinas que, de certa forma, imitam o ser humano na forma de pensar e de tomar decisões, das mais simples às mais complexas, abre um mundo de possibilidades para transformar e melhorar áreas como a saúde, a agricultura, a exploração espacial, o desporto, a indústria automóvel e outras.
Embora ainda não nos seja completamente óbvio, a IA já está muito presente no nosso dia a dia. Por exemplo, as redes sociais usam os chamados sistemas de recomendação que, em suma, priorizam o conteúdo que acreditam que o utilizador vai preferir. A decisão de apresentar determinado tipo de conteúdo a um utilizador específico tem em conta os seus dados pessoais (idade, sexo, etc.) e as interações que este tem com os diferentes conteúdos da plataforma. Além das redes sociais, os assistentes pessoais (por exemplo, Google Assistant, Siri, Alexa), smartphones, carros e muitos outros, já possuem alguma forma de IA incorporada neles. A presença da IA nas nossas vidas continuará a crescer à medida que vamos entendendo melhor o seu funcionamento e de que maneira a podemos aplicar aos diferentes cenários.
Quer se trate de um chatbot, reconhecimento ótico de caracteres (OCR), análise de texto, reconhecimento facial ou qualquer outro tipo de tarefa de IA, verificamos uma procura crescente destas funcionalidades de IA nas soluções que os nossos clientes nos pedem para criar, à medida que estes se tornam mais cientes da IA em geral e dos benefícios que esta pode trazer aos seus negócios. Com isto em mente, dedicámos parte do tempo que temos de autoaprendizagem durante a semana, para desenvolver um framework que pudesse resolver algumas das tarefas de IA, para poderem ser facilmente implementadas em vários projetos.
Neste artigo, vamos partilhar o nosso progresso, como abordámos o desenvolvimento deste framework, que tecnologias utilizámos, as tarefas que queríamos que o framework resolvesse, que conceitos aprendemos e que dificuldades encontramos ao longo do caminho.
Antes de começarmos a desenvolver o framework, foi necessário decidir as tarefas que queríamos que esta resolvesse nesta primeira fase, criar uma arquitetura e escolher as tecnologias a serem utilizadas para o seu desenvolvimento. Em termos de tarefas, decidimos que o framework deveria conseguir extrair entidades e intenções de qualquer texto e realizar manutenção preditiva. A decisão de extrair entidades e intenções é justificada pelo facto de ser uma das tarefas dentro de Robotic Process Automation (RPA). Basicamente, RPA consiste em software que pode ser facilmente programado para realizar atividades rotineiras, atualmente realizadas por humanos, de forma controlada, flexível e escalável. Esta tecnologia alivia os colaboradores de terem de realizar tarefas repetitivas e propensas a erros, e permite que estes se concentrem em tarefas com maior significado e importância, o que, em última instância, ajuda as organizações a serem mais produtivas e eficientes. A decisão de incluir a manutenção preditiva na fase inicial do framework prende-se com o facto de, atualmente, existirem vários equipamentos constituídos por inúmeros sensores, capazes de fornecerem dados necessários para determinar quando é que um determinado equipamento precisa de manutenção, para evitar futuras falhas.
Para compreender melhor estas duas tarefas e ter uma melhor ideia de como as resolver, tivemos que aprofundar e explorar algumas das abordagens mais utilizadas pela comunidade. A extração de entidades e de intenções é um subcampo do processamento de linguagem natural (PLN), um ramo da inteligência artificial cujo principal objetivo é dar aos computadores a capacidade de entender texto e diálogo de forma semelhante aos humanos. Para resolver tarefas relacionadas ao PLN, deparámo-nos com os seguintes conceitos e abordagens:
- Bags of words – é uma abordagem que transforma texto em matrizes. Esta abordagem não tira qualquer significado da ordem das palavras numa frase, no entanto, consegue detetar a presença ou a ausência das mesmas. Para utilizar esta abordagem, é necessário pré-definir um conjunto de palavras que se pretende que o modelo entenda. Esta abordagem é bastante limitada, uma vez que não consegue entender o contexto associado às palavras, porém pode ser útil para problemas mais simples como classificação de texto (por exemplo, para detetar se o texto de um determinado e-mail é spam ou não).
- N-grams – é uma sequência de N palavras. Um modelo baseado em N-gram prevê a ocorrência de uma palavra com base na ocorrência das N – 1 palavras anteriores. O preenchimento automático e a verificação ortográfica são alguns exemplos de tarefas onde este tipo de modelos pode ser utilizado.
- Word Embeddings – é um conjunto de técnicas em que palavras individuais são representadas por vetores de números reais num dado espaço vetorial. Palavras com significados semelhantes têm valores semelhantes no vetor.
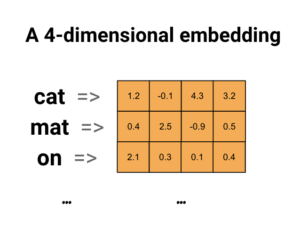
(Exemplo de word embedding)
- Embedding layers – são uma tipologia de camadas que podem ser incorporadas nas redes neurais para resolver tarefas específicas de processamento de linguagem natural. Os seus valores são ajustados recorrendo a algoritmos de backpropagation.
- Word2Vec – é uma família de arquiteturas de modelo e de otimizações que podem ser utilizadas para aprender word embeddings a partir de grandes conjuntos de dados. Os modelos Word2vec recebem palavras de um grande corpus de texto como dados de entrada, e aprendem a produzir a sua representação vetorial (word embedding).
- GloVe – é um algoritmo de aprendizagem não supervisionada utilizado para obter representações vetoriais (word embeddings) de palavras. Nesta abordagem, é criada uma extensa matriz de dados de coocorrência, que contém a contagem de cada palavra e a frequência com que esta aparece num determinado contexto dentro de um corpus de texto. O corpus de texto é geralmente avaliado da seguinte forma: para cada termo, são pesquisados termos de contexto num intervalo antes e depois do termo. Adicionalmente, às palavras que estão mais afastadas do termo original é dado um peso menor em comparação com as palavras mais próximas.
- Transformer – é uma arquitetura de redes neuronais cujo objetivo é resolver tarefas sequence-to-sequence enquanto lida com dependências de longo alcance de forma simples. Os modelos baseados nesta arquitetura utilizam “mecanismos de atenção” para calcular as representações dos dados de entrada e de saída, ao invés de utilizarem técnicas convolucionais ou de recorrência. Alguns exemplos de modelos que seguem esta arquitetura incluem o GPT-3, LaMDA, BERT, T5 e outros.
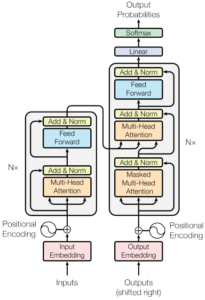
(Arquitetura Transformer)
A manutenção preditiva combina a ciência dos dados e análise preditiva para prever falhas num determinado equipamento, para poder ser planeada manutenção corretiva antes do ponto de falha. O objetivo é agendar a manutenção no momento mais conveniente e rentável, de modo a maximizar a vida útil do equipamento. A manutenção preditiva pode ser feita de duas formas: Classificação e Regressão. No primeiro método, tenta-se prever se uma falha é iminente nas próximas N etapas, e no segundo, tenta-se prever quanto tempo falta até a próxima falha.
Para resolver problemas de manutenção preditiva, é possível utilizar algoritmos de machine learning mais clássicos, como Support Vector Machine (SVM) ou K-Nearest Neighbors (k-NN ou KNN), ou pode-se seguir a rota do Deep Learning e utilizar auto-encoders, recurrent neural networks (RNN) ou redes long short-term memory (LSTM). Para lhe dar um pouco mais de contexto, fizemos um breve resumo de como funcionam os algoritmos anteriormente mencionados.
- Support Vector Machine – é um dos algoritmos de machine learning mais populares e pode ser utilizado tanto para tarefas de classificação como para tarefas de regressão. O seu principal objetivo é criar a melhor linha ou limite de decisão que possa segregar o espaço n-dimensional em classes, para que novos dados possam ser facilmente colocados na categoria correta no futuro. Este artigo demonstra como este tipo de algoritmo pode ser aplicado à manutenção preditiva.
- K-Nearest Neighbors – é um algoritmo de aprendizagem supervisionada, que utiliza a proximidade para fazer classificações ou previsões sobre o agrupamento de um ponto de dados individual. Este algoritmo pode ser utilizado para resolver problemas de regressão ou classificação, embora seja mais utilizado para o segundo tipo de problemas, partindo do pressuposto de que pontos semelhantes podem ser encontrados próximos uns dos outros. Este tipo de algoritmo pode ser aplicado a mecanismos de recomendação, reconhecimento de padrões e manutenção preditiva.
- Auto-encoder – é um tipo de rede neuronal não supervisionada que aprende a comprimir e a codificar dados eficazmente, e que depois aprende a reconstruir dados através de uma representação reduzida e codificada, para ser o mais próxima possível do original. É considerada uma rede neuronal não supervisionada, uma vez que os dados utilizados na fase de treino da rede não são anotados. Isto significa que o próprio modelo deve aprender a interpretar e a processar os dados de forma totalmente autónoma. Este artigo demonstra como pode este tipo de rede neuronal ser aplicado a tarefas de manutenção preditiva.
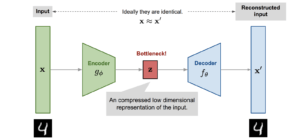
(Overview de um modelo Auto-encoder)
- Recurrent neural networks – é um tipo de rede neuronal onde as ligações entre as unidades formam um grafo orientado ao longo de uma sequência. Este fator permite que esses tipos de redes exibam um comportamento temporal dinâmico para uma sequência temporal. Estas redes neuronais são bastante utilizadas para resolver tarefas como o reconhecimento de fala ou o reconhecimento de escrita.
- Long-Short-Term Memory Networks – este tipo de redes são uma expansão das RNNs e utilizam unidades LSTM para memorizar informação durante longos períodos de tempo. Isto torna-as úteis na resolução de tarefas como o reconhecimento de fala, previsões da bolsa e muitas outras. A manutenção preditiva é também um bom exemplo da sua utilização, como pode ler aqui.
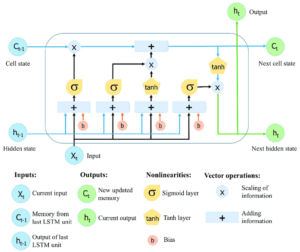
(Estrutura de uma rede LSTM)
Quanto à implementação do framework, determinámos que a melhor abordagem seria abstrair a utilização das bibliotecas open source de machine learning mais comuns. Com esta abordagem, podemos rapidamente acrescentar novos problemas para resolver e podemos optar por utilizar qualquer biblioteca sem termos que nos comprometer com uma específica. Isto foi alcançado através da criação de uma interface comum que pode ser utilizada por qualquer biblioteca, de forma que esta se comporte sempre da mesma forma, independentemente do problema que está a ser resolvido.
Com isto em mente, o diagrama seguinte mostra a arquitetura adotada:

O ProblemSolver é a classe principal e o ponto de entrada através do qual o programador interage com a ferramenta. Este terá que passar o problema que está a tentar resolver, os dados a serem usados e o formato dos mesmos. Internamente, os dados são convertidos num dataframe Pandas que depois é utilizado pela implementação concreta do ProblemInterface e que define as características de um problema. Para cada tipo de problema, é possível treinar um modelo personalizado, que será atribuído um ID e guardado em disco no formato pickle, ou é possível fazer uma previsão através de um modelo já existente em disco.
Os problemas que o framework resolve atualmente são:
- Extração de entidades – Extrai de um corpus de texto as entidades presentes, a sua localização e o seu tipo
- Classificação binária – Classifica uma instância de dados tabulares com a anotação adequada
- Regressão – Prevê o valor concreto de uma coluna para uma instância de dados tabulares
Em termos de tecnologias, decidimos utilizar Python para o desenvolvimento do nosso framework, uma vez que é uma das linguagens de programação mais utilizadas e é frequentemente utilizada para tarefas de machine e deep learning.
Além do Python, para a tarefa de extração de entidades utilizámos o Spacy, uma biblioteca de open source, amplamente utilizada e orientada para problemas de PLN, que tem uma particularidade bastante relevante e que não é muito comum noutras bibliotecas desta tipologia: o suporte da língua portuguesa. Para as tarefas de classificação binária e regressão, utilizámos o Pycaret, outra biblioteca open source e amplamente utilizada, que contém vários módulos para resolver tarefas no domínio da classificação, regressão, PLN, deteção de anomalias e muitos outras.
Como mencionado anteriormente, queríamos ter a liberdade de poder utilizar várias bibliotecas, já que algumas são mais adequadas para um tipo de tarefa do que outras, e também queríamos que a interação dos programadores com o framework fosse o mais fácil e direta possível. Como as implementações concretas do framework estão sempre por detrás da camada de abstração proposta, os programadores não precisarão de se preocupar com futuras atualizações dessas implementações e poderão facilmente integrar novas implementações, pois estas seguirão sempre a camada de abstração.
É importante destacar que o framework em questão está pronta para fornecer soluções úteis aos nossos clientes, no entanto, o seu desenvolvimento está longe de estar concluído. Pretendemos continuar a melhorar o framework, de modo a englobar outras das tarefas de machine learning mais relevantes, para que depois possam ser rapidamente incorporadas nos produtos dos nossos clientes. Relativamente ao futuro, pretendemos acrescentar novas tarefas a serem resolvidas, tais como OCR, classificação de imagens, deteção de objetos, tracking de objetos, e melhorar os resultados obtidos nas tarefas mencionadas ao longo deste artigo. Não perca os próximos artigos referentes às atualizações deste framework!











